画像認識の最適化実装を受託
2011年、静止画から特定の物体を検出する画像認識の最適化実装を受託しました。
Panasonicグループの開発部隊は、おおよそ製品開発と要素開発に分かれています。
- 製品開発 : 事業部 (ビジネス・ユニット)
- 要素開発 : 研究所 (開発センター)
私たち開発研究所(PSNRD)は、要素技術の研究開発から製品開発までを担当しています。要素技術に詳しい技術者や製品開発に詳しい技術者が多数います。そして、研究所の開発、事業部の開発、さらに研究所と事業部の間で技術をつなぐ開発をしています。
その中で私は、マイクロプロセッサのアーキテクチャに合わせてソフトウェアを再構成する最適化実装を得意としています。すなわち、要素技術を理解して具体的な製品開発に最適な形にして組み込むのです。TI C64x DSP向けに画像認識を最適化実装したこともあります。
事業部では、カメラで物体を検出するシステムを開発していました。開発センターが開発した「静止画物体検出」を組み込んだところ、画像認識部の処理時間が約52msも必要として、30fpsで動作するシステムを実現できない状態でした。
研究所の開発した要素技術は、パソコンで動作する汎用的なアルゴリズムです。事業部が商品化する組み込みシステムのプロセッサに特化していません。
そこで、私が画像認識部を最適化実装することになり、開発センターの技術を事業部につなぐことになりました。
システムを実現するためには、画像認識部の処理時間は20ms以下にしなければなりませんでした。
静止画物体検出の仕組み
基本的なアルゴリズム
静止画物体検出の基本的なアルゴリズムの概要を下記に示します。
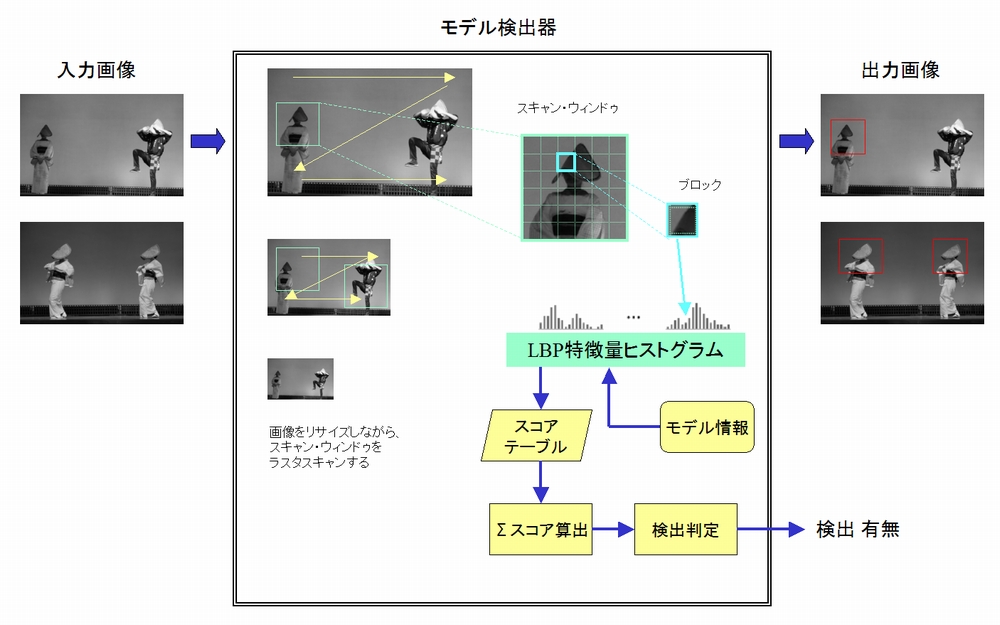
静止画物体検出
モデル検出器は、入力したグレースケール画像をLBP特徴量に変換して、輝度の分布(ヒストグラム)により画像の特徴を捉えます。
入力画像に対してスキャン・ウィンドゥをラスタースキャンします。スキャン・ウィンドゥは、ブロックから構成しておりブロック単位にLBP特徴量に変換して輝度の分布であるヒストグラムを生成します。
モデル検出器の内部には、事前に大量の(ポジティブ or ネガティブ)画像で統計学に基づく学習を行ったモデル情報があります。モデル情報を元に、LBP特徴量ヒストグラムからスコアテーブルを参照して、スコアを算出して検出判定をします。
いろいろな大きさの対象物を検出するため、入力画像を数段階にわたりリサイズして、以上の処理を繰り返します。
LBP特徴量とは
LBP(Local Binary Pattern)とは、1994年に提案された手法でローカル・バイナリー・パターンのことです。
- 画像の局所的な特徴を抽出できる
- 画像の照明変化の影響を受けにくい
実際に使用したLBPは、検出精度を向上するためにパターンの形や算出方法を工夫したLBPです。
ここでは、教科書で説明されている基本形のLBPについて説明します。

LBP特徴量の算出
グレースケール画像は、各画素が256階調の輝度値です。暗い画素は輝度値が小さく、明るい画素は輝度値が大きいです。
ある画素のLBPは、3×3領域の近傍8画素から算出します。8近傍のおのおの周辺画素について、中心画素と比較します。
- 周辺画素が中心画素以上の場合 : 「1」
- 周辺画素が中心画素未満の場合 : 「0」
8近傍を時計回りに比較結果のビットをLSBから並べます。この例では、ビット列は「00011101」となります。10進数に変換すると、「29」になります。この値が、中心画素のLSB値です。
3×3領域を1画素ごとにずらして、入力画像に対するLBP特徴量を算出します。
左側のlena画像をLBP変換すると、右側のような画像となります。
静止画物体検出の最適化実装
ターゲットのPowerPCマイクロプロセッサ
組み込み機器のターゲットのマイクロプロセッサはPowerPCです。
一般的に最適化実装するときに高速化の最も効果の高い手段として、SIMD(Single Instruction Multiple Data)命令の利用があります。SIMD命令は、ひとつの命令で複数のデータを同時に処理することができます。パソコンで使用しているx86系プロセッサでは、SSE命令やAVX命令などがSIMD命令です。
PowerPCマイクロプロセッサは初めて使用するので、命令セットアーキテクチャのマニュアルを読んで調査しました。残念ながら、使用するPowerPCマイクロプロセッサではSIMD命令は使用できませんでした。
PowerPCは、RISC(Reduced Instruction Set Computer)系のマイクロプロセッサです。
・32bit汎用レジスタが32本
・レジスタ間で演算
・メモリアクセス命令は、ロード命令とストア命令だけ
・2個の演算ユニットを搭載し7段パイプライン
最適化実装で処理時間を短縮する手法はいくつかありますが、経験的にSIMD命令が使えないと画期的な高速化は難しいものです。
最適化実装の手順
最適化実装の手順は、以下のようになります。
- コンパイルオプションを調べて、コンパイラが効率的なオブジェクトコードを出力できるようにします。
- プロファイルを取得して、各モジュール別に処理量や繰り返し回数を把握することにより、どのモジュールから改善すると効率的か判断します。
- コンパイラが出力したアセンブラコードを解析して、効率的なオブジェクトコードになっているか調べます。
- 実装方法を工夫して、効率的なオブジェクトコードになるようにソースコードを修正します。
プロファイルによる処理時間の調査
プロファイルを取得すると、画像認識部の処理時間である約52msのうち、LBP特徴量算出は約17msで全体の1/3の処理時間を占めていました。
最適化実装する定石は、効果の高いモジュールから最適化することです。すなわち、処理回数が数回の部分を高速化しても、全体としての効果は少ないからです。処理回数が多い部分を高速化すると、全体としての効果は高くなります。
LBP算出アルゴリズムは、画面内部をスキャン・ウィンドゥを移動しながらLBP特徴量を算出しているので、何回もループしている処理です。さらに、入力画像をリサイズしながら、この処理を行います。従って、処理回数はとても多いので、ループ本体のコア部分の処理時間を短縮することにより、全体として高い効果を発揮します。
最適化実装の結果
開発に着手した当時は、最適化実装により高速化するのは困難と思えました。性能目標は、処理時間を約52ms から 20ms以下にすることです。
LBP特徴量算出の最適化実装を検討しているときに、夢の中でものすごいアイデアが浮かびました。
SIMD命令が無いのならば、ソフトウェアで「ソフトSIMD」を実現すれば良いのです
翌日、このアイデアを実現してみたところ、とても効果がありました。「ソフトSIMD」のアイデアに加えて、下記手法で最適化実装しました。
- データメモリの配置をキャッシュラインサイズの32バイトアライメントして、キャッシュ効果を高める
- プリフェッチ命令で、あらかじめ使用するデータメモリをキャッシュにロードする
- ループを手動でアンローリングして、ループのオーバーヘッドを抑止する
- ループの中でパイプラインを乱す原因のジャンプ命令を必要最小限にする
その結果、LBP特徴量算出の処理時間は 17ms→7ms になり、約2.4倍に高速化することができました。その他の部分もアイデアを組み込んで「静止画物体検出」全体を最適化実装した結果、処理時間は 52ms→17ms となり約3倍に高速化することができました。
目標の20ms以下を達成できて、事業部の開発しているカメラで物体を検出するシステムを無事に商品化できました。
夢のアイデア 「ソフトSIMD」について
LBP特徴量算出のソースコードの読んでいたときに、メモリアクセスが多いことが処理時間を要している原因なのだと気がつきました。
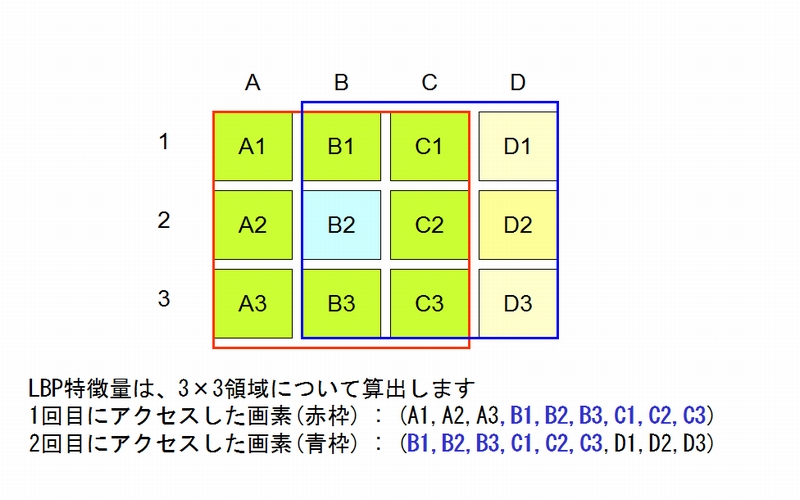
3×3領域の画像アクセス
上記図で説明します。3×3領域ごとにLBP特徴量の算出を行います。
- 最初のブロックは赤い枠で示すように、(A1,A2,A3,B1,B2,B3,C1,C2,C3)の9画素をアクセスします。
- 次のブロックは青い枠で示すように、(B1,B2,B3,C1,C2,C3,D1,D2,D3)の9画素をアクセスします。
直前にアクセスした9個の画素に対して、6個については同じ画素を再度アクセスしているのです。
一般的にRISC系プロセッサでは、内部の演算処理は1クロックであるのに対して、メモリアクセスは数クロックを要するものです。ロードするメモリがすでにキャッシュにフェッチされていた場合でも数クロック必要であり、ミス・ヒットした場合は、キャッシュにロードされるまでロード命令はストール(待機)します。
このアルゴリズムでは、メモリアクセスのために内部処理が待たされているケースが多いのだろうと想像します。直前にロードした画素データを保存しておいて、次回のブロックでは新規の3画素だけロードします。そうすれば、メモリアクセスで待たされるケースは格段に削減できるだろうと考えました。
入力画像は、グレースケール画像で1画素は8bitです。レジスタは32bitなので、最大で4画素までひとつのレジスタに入れることができます。次のブロックを処理するときは、レジスタを左シフトして左側の不要となった画素を捨て、右側に新規の画素を詰め込むことにより、直前にロードした画素データを再利用できます。
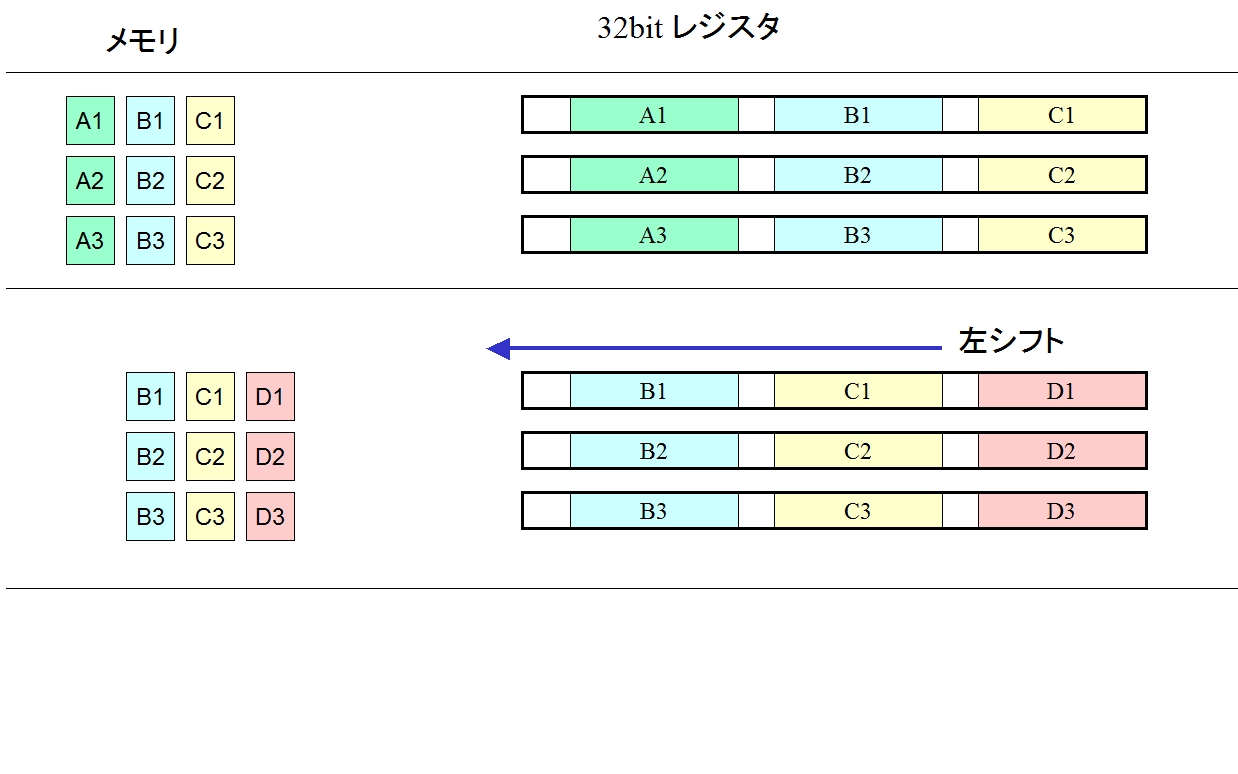
レジスタに画像パック
![]()
・・・その夜の夢の中の話です・・・
例えば、32bitレジスタに3個の8bit画素データを格納したと仮定します。LBP特徴量の算出は、8近傍の周辺画素と中心画素の大小関係によって「0/1」の値が決まるわけですから、32bitレジスタでまとめて3個の画素を引き算して求めることはできないだろうか?
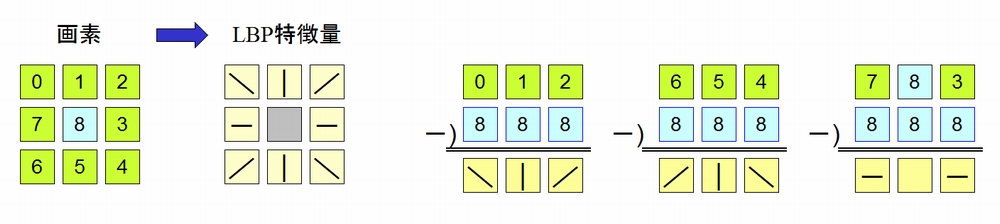
画素からLBP特徴量
すなわち、SIMD命令は無いけどソフトウェアで「ソフトSIMD」を実現できないものだろうかと考えました。
単純に引き算すると、右側の画素のボローが左側の画素の引き算に影響してしまいます。
そうか・・・ボローの影響を食い止める壁を間に挟めば、実現できるのでは・・・・
・・・ここで、目が覚めました・・・
![]()
翌朝、なんかすごいアイデアを思いついたのではと考えながら出社しました。そして、そのアイデアを具体的に図に書いて、間違いが無いか検証しました。
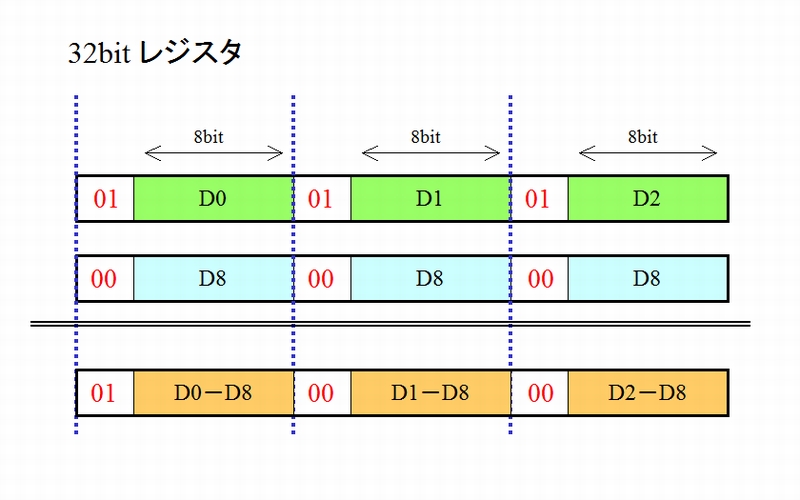
ソフトSIMD
32bitのレジスタを10bitずつ3つに区切り3個の8bitデータをパックします。
各データの前に2bitでボローを抑止する制御ビットを配置します。
被減算側を「01」、減算側を「00」とします。
- D2 > D8 の場合、ボロー抑止制御ビットは「01」
- D2 = D8 の場合、ボロー抑止制御ビットは「01」
- D2 < D8 の場合、ボロー抑止制御ビットは「00」
すなわち、ボロー抑止制御ビットがあるおかげで上位のデータの減算には影響を与えることはありません。そして、ボロー抑止制御ビットを参照するだけで、データの大小関係を判定することができます。
ひとつの演算で3つのデータの大小関係を判定できるというのは、SIMD命令と同等です。私が個人的に、この仕組みを「ソフトSIMD」と呼びました。ソフトウェアの専門用語には無い、私の造語です。
頭の中で、もやもやしていた課題に対して、夢の中でヒントを生み出したのです。
早速、効果を確かめるために、このアイデアのサンプルプログラムを書いて確認しました。
メモリアクセスを減らしたことと、一度に3画素の大小関係を判定する「ソフトSIMD」の効果で処理時間は大幅に短縮することができました。
void image_lbp1(int iw,int ih ,unsigned char *pbufSrc ,unsigned char* pbufDst)
{
unsigned char (*puSrc )[IMAGE_WIDTH_MAX] = (unsigned char(*)[IMAGE_WIDTH_MAX])pbufSrc;
unsigned char (*puDst )[IMAGE_WIDTH_MAX] = (unsigned char(*)[IMAGE_WIDTH_MAX])pbufDst;
//
for(int iy=1; iy<ih-1; iy+=1)
{
for(int ix=1; ix<iw-1; ix+=1)
{
unsigned char lbp8 = 0;
unsigned char uc = puSrc[iy][ix]; // |08|
if (uc <= puSrc[iy-1][ix-1]) { lbp8 += (1<<0); } // [-1] |00|__|__|
if (uc <= puSrc[iy-1][ix ]) { lbp8 += (1<<1); } // [-1] |__|01|__|
if (uc <= puSrc[iy-1][ix+1]) { lbp8 += (1<<2); } // [-1] |__|__|02|
if (uc <= puSrc[iy ][ix+1]) { lbp8 += (1<<3); } // [ 0] |__|__|03|
if (uc <= puSrc[iy+1][ix+1]) { lbp8 += (1<<4); } // [+1] |__|__|04|
if (uc <= puSrc[iy+1][ix ]) { lbp8 += (1<<5); } // [+1] |__|05|__|
if (uc <= puSrc[iy+1][ix-1]) { lbp8 += (1<<6); } // [+1] |06|__|__|
if (uc <= puSrc[iy ][ix-1]) { lbp8 += (1<<7); } // [ 0] |07|__|__|
puDst[iy][ix] = lbp8;
}
}
}
ソフトSIMD版の改良型を下記に示します。
void image_lbp2(int iw,int ih ,unsigned char *pbufSrc ,unsigned char* pbufDst)
{
unsigned char (*puSrc )[IMAGE_WIDTH_MAX] = (unsigned char(*)[IMAGE_WIDTH_MAX])pbufSrc;
unsigned char (*puDst )[IMAGE_WIDTH_MAX] = (unsigned char(*)[IMAGE_WIDTH_MAX])pbufDst;
//
for(int iy=1; iy<ih-1; iy+=1)
{
unsigned char* pH = &puSrc[iy-1][0];
unsigned char* pC = &puSrc[iy ][0];
unsigned char* pL = &puSrc[iy+1][0];
//
uint32 d00_01_02 = pH[0]+0x100; // |00|@@|d00|@@|d01|@@|d02|
uint32 d07_08_03 = pC[0]+0x100; // |00|@@|d07|@@|d08|@@|d03|
uint32 d06_05_04 = pL[0]+0x100; // |00|@@|d06|@@|d05|@@|d04|
d00_01_02 = (d00_01_02<<10) + (pH[1]+0x100);
d07_08_03 = (d07_08_03<<10) + (pC[1]+0x100);
d06_05_04 = (d06_05_04<<10) + (pL[1]+0x100);
//
for(int ix=1; ix<iw-1; ix+=1)
{
d00_01_02 = (d00_01_02<<10)+(pH[ix+1]+0x100);
d07_08_03 = (d07_08_03<<10)+(pC[ix+1]+0x100);
d06_05_04 = (d06_05_04<<10)+(pL[ix+1]+0x100);
//
uint32 d08 = (d07_08_03>>10)&0xff;
uint32 d08_08_08 = (d08<<20) + (d08<<10) + d08;
//
uint32 sH = d00_01_02 - d08_08_08; // |d00|d01|d02| - |d08|d08|d08|
uint32 sC = d07_08_03 - d08_08_08; // |d07|d08|d03| - |d08|d08|d08|
uint32 sL = d06_05_04 - d08_08_08; // |d06|d05|d04| - |d08|d08|d08|
//
int d0_d8 = (sH>>(20+8-0))&0x01; // (d00 < d08)
int d1_d8 = (sH>>(10+8-1))&0x02; // (d01 < d08)
int d2_d8 = (sH>>( 0+8-2))&0x04; // (d02 < d08)
int d3_d8 = (sC>>( 0+8-3))&0x08; // (d03 < d08)
int d4_d8 = (sL>>( 0+8-4))&0x10; // (d04 < d08)
int d5_d8 = (sL>>(10+8-5))&0x20; // (d05 < d08)
int d6_d8 = (sL>>(20+8-6))&0x40; // (d06 < d08)
int d7_d8 = (sC>>(20+8-7))&0x80; // (d07 < d08)
unsigned char lbp8 = (d0_d8)+(d1_d8)+(d2_d8)+(d3_d8)+(d4_d8)+(d5_d8)+(d6_d8)+(d7_d8);
puDst[iy][ix] = lbp8;
}
}
}
最後に
最適化実装する技術者として必要なスキルは、いくつかあります。
- 認識アルゴリズム等のコア・アルゴリズムの理解力
- アルゴリズムを最適な形で組み込むためのソフトウェア技術力
- マイクロプロセッサのアーキテクチャを理解して効率的に利用する力
- C/C++言語でソースコードを記述しても、マイクロプロセッサで機械語として動作している状態を見通す力
- 数々の高速化手法を知りつくして、経験的に応用する力
上記スキルに加えて、
- 解決困難な課題に直面しても「乗り越えられない壁は無い」との技術者魂
その技術者魂が、課題解決のためのユニークなアイデアを生み出して、解決へ導くのです。今回の開発では、「ソフトSIMD」という考え方のアイデアで大きな壁を乗り越えることができました。