初めての画像認識
2006年、動画像から移動物体を検出・追跡する画像認識アルゴリズムをTI DSPに最適化実装する開発を受託しました。

Texas Instruments
私にとって初めての画像認識アルゴリズムでしたので、経験不足のために認識アルゴリズムの理解など苦労しました。しかし、ソフトウェア理解力により早期に解析を進めて、ひらめきや工夫を組み込んで最適化実装することにより 148ms → 38ms と約4倍の高速化を達成できました。
ビデオモーション検知
ビデオモーション検知(VMD : Video Motion Detector)技術は、動画像から移動物体の検出および追跡を行う技術です。本技術は、セキュリティ事業の監視カメラシステムなどに搭載しています。監視カメラで撮影した動画像から移動物体の検出および追跡を行うことにより、侵入者検知・人物追跡、置き去り・持ち去り検出などを行い、事故・犯罪への対応や未然防止を図っています。
開発の経緯
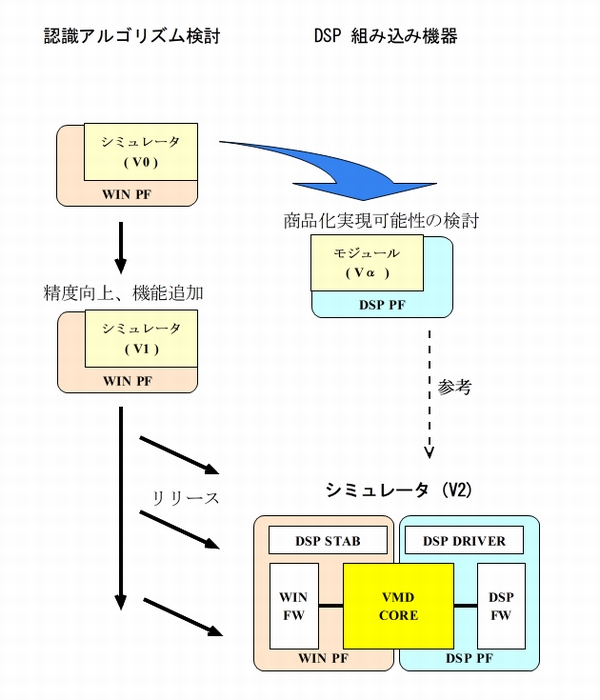
PSS社セキュリティ部門と金沢研究所のMさんは、ビデオモーション検知アルゴリズムを評価検討するために、Windowsで動作するPCシミュレータ(V0)を開発しました。そして、いろいろなシーンの評価画像を用いて評価を繰り返していました。
検知アルゴリズムが実用レベルになったころ、組み込み機器による商品化フェーズに進むために、セキュリティ部門の開発センターにて商品化実現可能性検討を行いました。
実現可能性検討は、Windowsで動作する検知アルゴリズムの一部分をTIのTMS320DM642 Evaluation Module上に移植したDSPモジュール(Vα)にて実施します。TMS320DM642は、C64xシリーズのTI DSPを搭載した評価ボードです。
商品の目標仕様は、動画像から移動物体の検出・追跡を10fps間隔で2チャンネルに対して実施することです。検知アルゴリズムは、10fps間隔で動作しますので1フレームあたり100ms以内で処理することになります。さらに、2チャンネルを交互に検知しますので、1フレームあたり50ms以内で処理することが目標となります。
検知アルゴリズムのコードをそのまま搭載した状態では、1フレームあたりの処理時間は最大で4秒だったそうです。そのC言語ソースコードをTI DSP向けに最適化実装し、最適化コンパイラオプションモードでビルドすることにより、約52msで動作するようになり商品化フェーズに進むことになりました。
ビデオモーション検知ソフト
そのころ、PCシミュレータ(V0)をベースとして検知精度をさらに高めて新機能を追加したPCシミュレータ(V1)をTさんが開発中でした。
商品化は、PCシミュレータ(V1)の最新検知アルゴリズムをTMS320DM642 DSPに搭載することになり、私が最適化実装を担当しました。商品化実現可能性検討で開発したDSPモジュール(Vα)のノウハウが参考になります。
今回の開発は、検知アルゴリズムをDSPに移植して最適化実装するだけではありません。ベースとなるPCシミュレータ(V1)は開発中ですので、段階的にリリースされます。
そこで、PCシミュレータとDSPモジュールのソースコードを一本化して、同じソースコードを共有します。Windows用にビルドすると、アルゴリズムの評価検討ツールのシミュレータとなります。DSP用にビルドすると、実機のDSPモジュールを生成します。
そのために、ソフトウェアを再構築しました。
- WIN FrameWork : Windows用環境フレームワーク
- DSP FrameWork : DSP用環境フレームワーク
- VMD CORE : 検知アルゴリズムのコア部
- DSP DRIVER : DSP依存コード(DMA、SIMD命令など)
- DSP STUB : DSP依存コードをPCで動作させる (DMA相当のメモリコピー)
また、アナログの画像入力系の他に、毎回同じ画像を入力するためにファイルから画像入力する系を作りました。
- 不具合発生時の再現性を確保するため
- WIN PFとDSP PFで同じ検出結果となることの確認のため
このようにして新しいPCシミュレータ(V2)は、従来の評価用ツールとして利用できると共に商品に実装するDSPモジュールを生成することになります。MさんとTさんから検知アルゴリズムの説明を受けながら、Tさんと協力してPCシミュレータ(V2)を構築していきます。
TI C64x DSPについて
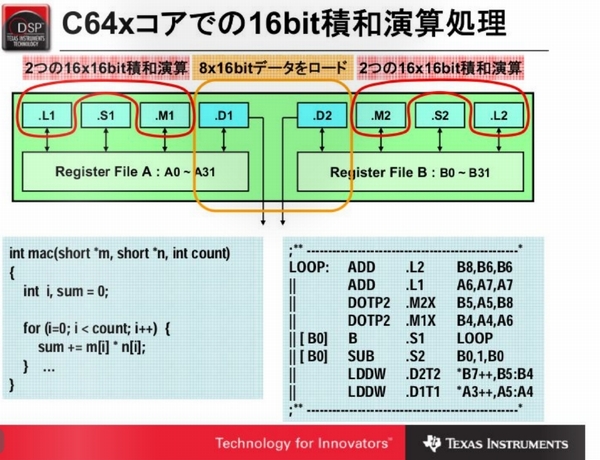
TMS320DM642は、TI社のC64xアーキテクチャのDSP(Digital Signal Processor)です。C64x DSPは、高性能な固定小数点演算処理を必要とする音声・映像の信号処理を高速に実行することができます。

TI C64x DSP
- 大容量の汎用レジスタ : 32bitレジスタ 32本×2セット (A0~A31 ,B0~B31)
- 8つの演算ユニット : 4ユニット(.L .S .M .D)×2セット
- 2つのデータパス : Data Path A / Data Path B
- L1D データメモリ : 64-bitバス×2パス(.D1 / .D2) キャッシュ、または、データメモリ
- L1P 命令メモリ : 256-bitバス(32bit×8命令) キャッシュ、または、命令メモリ
RISC(Reduced Instruction Set Computer)系のアーキテクチャに加えて、VLIW(Very Long Instruction Word)アーキテクチャを採用しています。VLIWのすごいところは、命令メモリから最大8命令を同時にフェッチ・ディスパッチ・デコードして、8個の演算ユニットを同時に実行することができます。うまく組み合わせれば、1サイクルに8命令同時に実行することが可能で、通常のプロセッサに比べて8倍の処理能力があります。
アセンブラ言語でプログラマがこの組み合わせを考える必要はなく、最適化コンパイラがC言語ソースプラグラムから最適な組み合わせを生成します。私がこれまで経験したことのない、すごいプロセッサです。
TI C64x DSP サンプル
ソフトウェアパイプライン(Software Pipelining)最適化技法により、ループ部について実行ユニットで効率良く実行できるように命令スケジューリングします。上記の例では、左側のC言語ソースプログラムから右側のアセンブラコードを生成します。アセンブラで左端に「||」を付加した命令は同じスロットとなります。この例では8命令を同時実行するので、1ループあたり1サイクルで実行することができます。
ソフトウェアパイプラインの間は割り込み禁止状態となり、割り込み発生によりパイプラインが乱れないようになっています。
処理時間計測系は、1msごとの割り込みを利用してカウントアップしています。割り込み禁止区間の影響がないか心配になり調べてみると、ソフトウェアパイプラインが10ms程度のループ処理において、実際の処理時間よりも計測時間が短くなる現象を発見しました。CLKマネージャの1tickの時間を1ms→100msに変更することにより、割り込み禁止区間の影響を抑止することができました。
商品化実現可能性検討のDSPモジュール(Vα)を再計測すると、52msではなく実際には79msで動作していました。この事実で、最適化実装のハードルが上がったことになります。
C64x DSP最適化実装
最適化実装は、いくつかの手法を組み合わせてケース・バイ・ケースで試行錯誤しながら実施しました。
ソフトウェアパイプライン
コンパイラが最適なコードを生成するように#pragma文でプログラム構造情報を指示します。そして、コンパイラが生成したアセンブラリストを分析してC言語ソースプログラムの記述順を組み替えます。すなわち、ソフトウェアパイプラインを効率良く生成するようにソースプログラムを修正します。
TIマニュアルに、下記のような指針を書いています。
【ソフトウェアパイプラインが生成されない条件について】
① ループではない場合
② switch文やbreakを含むループ
③ Intrinsics関数(組み込み関数)以外の関数コールを含むループ
④ ループ処理を開始するために前のループ処理の結果を必要とするような場合
⑤ 複雑な条件分岐を含むループ
⑥ ループ内のコードサイズが大きいとき
⑦ ループ内で条件によりループカウンタの値が変更される
⑧ レジスタの本数が足りない場合
なるべく単純なループにすることにより効率良いコードが生成されます。
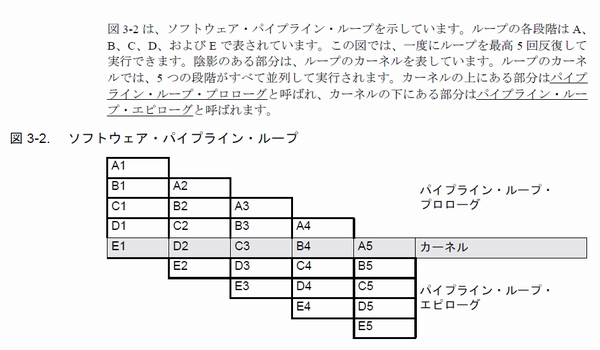
TI C64x DSP ソフト・パイプライン
ループ内の処理がA→B→C→D→Eの5つの処理で構成し、5回反復する場合の例です。ループカーネル(KERNEL)部で5つの処理を並列処理するコードを生成し、ループ前にプロローグ(PROLOG)部、ループ後にエピローグ(EPILOG)部を生成します。
Intrinsics関数
Intrinsics関数(組み込み関数)というアセンブラ命令に対応したSIMD命令を直接呼び出して効率の良いコードを書きます。アセンブラレベルの思考でアルゴリズムを組み立てることになりますが、レジスタの割り当てはコンパイラの最適化に任せることができます。
内部高速メモリの利用
Level 1 Data Memory(L1D)は、データキャッシュまたは高速な内部メモリとして使用することができます。高速な内部メモリとして使用頻度の高いデータを配置することにより、データアクセスが効率良く行うことができます。
Level 1 Program Memory(L1P)は、プログラムキャッシュまたは高速なプログラムメモリとして使用することができます。
メモリストールの抑止
内部演算処理は1サイクルで実行するのに対して、メモリアクセスは数サイクルを必要とします。アクセスするメモリがすでにキャッシュにフェッチされていた場合でも数サイクル必要であり、ミス・ヒットした場合は、キャッシュにロードされるまでメモリアクセスはストール(待機)します。高速な内部メモリ(L1D)を使用した場合でも、数サイクル必要となります。
ロード命令の直後にそのデータを演算する命令を配置した場合、ロードが完了するまでストールが発生することになります。従って、ロード命令と演算命令の間に他の処理を挟むことにより、ストールを抑止することができます。
最適化実装の例
画像Aと画像Bのフレーム間差分をバッファDに格納するコードの最適化を例とします。画像サイズは、(xm)×(ym)とします。QVGAの場合は、xm=320、ym=240です。
コンパイラが最適なコードを生成するように#pragma文でループの繰り返し情報を指示し、さらにSIMD演算で4画素を同時に計算することにより、なんと21倍も高速化できました。
オリジナルコード
for(y=0; y<ym; y++)
{
for(x=0; x<xm; x++)
{
ix = y*xm + x;
if(abs(A[ix]-(B[ix])) > (th))
{
D[ix]=255;
}
else
{
D[ix]=0;
}
}
}
コンパイラは、1番内側のループをソフトウェアパイプライン化します。
- LOOP PROLOG : 9 step
- LOOP KERNEL : 8 × 320 step
- LOOP EPILOG : 4 step
LOOP部は、9+8×320+4=2573 stepとなります。全体の処理は、外側のループで240回繰り返しますので2573×240=617520 step となります。
最適化 (1)
二重ループを一重ループにします。配列をポインタアクセスにします。
#pragmaで、ループ回数の情報(最小を2回、倍数を2回)を与えます。すなわち、0回ループは無しで偶数回とします。
#pragma MUST_ITERATE(2, (320*240) ,2)
for(p=0; p<ym*xm; p++)
{
if(abs( (*pA++)-(*pB++) ) > (th))
{
d=255;
}
else
{
d=0;
}
*pD++ = d;
}
ループ KERNEL部が3、ループ Unroll 2x でループ回数が半分になりました。
- LOOP PROLOG : 3 step
- LOOP KERNEL : (Unroll 2x) 3 × 320 × 240 ÷ 2 = 115200 step
- LOOP EPILOG : 1 step
全体の処理は、3+(3×320×240÷2)+1=3+115200+1=115204 step となります。オリジナルコードに比べて、617520→115204 step となり、約5.3倍に高速化しました。
最適化 (2)
Intrinsics関数を使用して、SIMD命令で4画素を同時に算出します。
#pragmaで、ループ回数の情報(最小を4回、倍数を4回)を与えます。
#pragma MUST_ITERATE(4, (320*240) ,4)
for(p=0; p<ym*xm; p+=4)
{
dA = _mem4_const(pA);
dB = _mem4_const(pB);
dD = _subabs4(dA ,dB);
_mem4(pD) = _xpnd4(_cmpgtu4(dD,th4));
pA += 4;
pB += 4;
pD += 4;
}
ループ KERNEL部が3、ループ回数が1/4になりました。
- LOOP PROLOG : 3 step
- LOOP KERNEL : 3 × 320 × 240 ÷ 4 = 57600 step
- LOOP EPILOG : 8 step
全体の処理は、3+(3×320×240÷4)+8=3+57600+8=57611 step となります。オリジナルコードに比べて、617520→57611 step となり、約10.7倍に高速化しました。
最適化 (3)
画像数は8の倍数ですので、1回のループで4画素×2回の処理を行います。
#pragmaで、ループをアンロールします。
#pragma MUST_ITERATE(4, (320*240) ,4)
#pragma UNROLL(2)
for(p=0; p<ym*xm; p+=4)
{
dA = _mem4_const(pA);
dB = _mem4_const(pB);
dD = _subabs4(dA ,dB);
_mem4(pD) = _xpnd4(_cmpgtu4(dD,th4));
pA += 4;
pB += 4;
pD += 4;
}
ループ KERNEL部が3、ループ回数が1/4になりました。
- LOOP PROLOG : 3 step
- LOOP KERNEL : 3 × 320 × 240 ÷ (4×2) = 28800 step
- LOOP EPILOG : 9 step
全体の処理は、3+(3×320×240÷8)+9=3+28800+9=28812 step となります。オリジナルコードに比べて、617520→28812 step となり、約21.4倍に高速化しました。
ビデオモーション検知アルゴリズムの最適化実装
DSPモジュール(Vα)のノウハウを参考にしながら、PCシミュレータ(V2)を構築しました。
初期のころは、1フレームの処理時間は最大で148msも要していました。目標は、50ms以内になるように最適化実装することです。
処理時間のプロファイルを解析して処理量の大きいモジュールから順に最適化実装を施していきます。最適化実装のノウハウを組み込むことにより処理時間は少しずつ短くなってきます。しかし、ある程度の最適化実装が進むと、まるで「乾いた雑巾を絞る」ように限界が見えてきます。そこで、汗をかき知恵を出し、アイデアを創出して工夫することにより、限界の壁を越えることができます。
いくつかの工夫をメモしておきます。
ラベリング処理は、独自アルゴリズムを創出して2画素同時に判定することにより高速化することができました。
膨張伸縮処理は、いったんバイナリパターンに変換することにより32bit(32画素)を同時に膨張伸縮し高速化しました。
背景差分処理は、内部メモリにダブルバッファを用意して、背景差分算出中に次に処理する画像部分を内部メモリにDMA転送する工夫で、データ転送と背景差分算出を同時に行い、メモリアクセスでストールすることなく、高速な処理を実現することができました。
その他、いろいろな工夫を組み込むことにより、最終的に 148ms → 38ms と約4倍の高速化を達成できました。
最後に
ビデオモーション検知アルゴリズムをTI DSPへ最適化実装することができました。ソフト・ソリューションで実用的に画像認識アルゴリズムを実現できる時代がようやく来ました。
今回の開発で、大事なことを学びました。本当の知恵と言うものは汗(経験)から出るものです。試行錯誤しながら、もがき苦しみ知恵を絞りました。
こんなこともありました。お風呂に入ってリラックスしているときに、壁のタイルが画素に見えて無意識のうちに最適化アルゴリズムを考えていました。
そして、ひらめきや工夫を生み出す苦しみと喜びを感じました。プロセッサへの最適化実装は、私のひとつの武器となりました。
ピンバック: PowerPCによる画像認識の最適化実装 | ある計算機屋さんの手帳
ピンバック: 画像処理 膨張・収縮アルゴリズム | ある計算機屋さんの手帳